
Harnessing the Power of Content as Code

During this series on content quality in a digital world, we’ve discussed what content quality is and several methods for ensuring that it’s preserved throughout your digital projects, such as creating a production sample ahead of time and proofing your digital content in new ways. In this last post of the series, we’re going to dig into the fundamental shift that is driving the changing approaches to content quality: content as code.
Understanding Content as Code
If I told you to picture “content”, what’s your instant reaction? You’re probably seeing paragraphs of text, maybe an image or two, all arranged on something that looks like a page, whether on a sheet of paper, a Word or Google doc, or a web page (like the one you’re reading right now). What you probably don’t picture is this:
<h3>Understanding Content as Code</h3><p>During this series on content quality in a digital world, we’ve discussed <a href=”https://blog.inklingelemdev.wpengine.com/2014/06/how-to-establish-digital-content-quality/”>what content quality is</a> and several methods for ensuring that it’s preserved throughout your digital projects, such as <a href=”https://blog.inklingelemdev.wpengine.com/2014/06/test-drive-content-with-production-samples/”>creating a production sample</a> ahead of time and <a href=”https://blog.inklingelemdev.wpengine.com/2014/07/beyond-page-breaks-proofing-digital-content/”>proofing your digital content</a> in new ways.
And yet, this marked up version, filled with h3’s and href’s and other bits of code, is what content today truly is. In order to move content beyond a single Word doc and into the hands of any reader, on any device, the text, images, and other elements need to be infused with what is known in coding as a markup language.
Harnessing the Power of Content as Code with Markup Languages
Markup languages provide instructions to machines on how to display and structure content; without those instructions, no machine in the world would be able to show you content as it’s easiest to comprehend–with fonts, indents, styling, appropriately-placed images and graphs or hyperlinks.
Because markup languages act as content’s infrastructure, they allow us to reproduce that content at scale without building it anew for different devices. This is a huge step forward for efficiency, much like how the printing press put an end to producing books one at a time. What the printing press couldn’t do, however, was correct mistakes after those books had been printed and shipped out. But markup languages, like all languages, are made up of recurring patterns that allow us to identify and alter the content’s features in real time. For example, we can make sweeping cosmetic adjustments, such as all bolded words become italicized, or major shifts, such as re-styling tables and graphs.
Identifying patterns in the markup language requires some basic knowledge of code. Think of it as the equivalent to completing any introductory language course–you may not know how to speak it or write it, but you can identify the language when you see it. Markup languages may not have accents or umlauts, but they have several distinct qualities that make for easy target searches. For example, each component begins with tags; each component has an identifier built into the markup language (p for paragraph, li for a list item, section for the start of a sidebar, and so on); each component has a specific class that makes it operate in particular ways; and so on. All of these components can serve as the target of a search. Instead of just searching for words, you can now search for all <li> (list items) or an image within all sidebars.
Before I dive further into some tangible benefits we’ve found for treating content as code when working towards content quality, however, I want to make sure one thing is clear: without the direction and involvement of human editors, none of this works. Though we’ll discuss some technical tools and automated processes, all of this is based on the assumption that a human editor has spotted a problem or error and is looking for a way to solve that problem globally. “Content as code” doesn’t mean people stop creating, editing and distributing content. Rather, by encoding content, humans can spend more time on what we’re good at, such as development and design, or thinking of clever ways solve an error, and less time on what software is good at, like finding repeated errors quickly and accurately within thousands of pages.
At Inkling, our editorial teams harness the power of content as code in order to ensure that quality is consistently high. While there are many ways we do this, I’ll share two examples here: running built-in unit reports and developing unique editorial tools to check common problem areas.
The Unit Test: Scalable and Automatic QA
Being able to search by components means that your search will be comprehensive, but how do you make it efficient? One way is to automate searches for common errors, instead of running individual searches for each of these issues in every project. This QA strategy is known in software development as a unit test, which is an automated test programmed to find bugs in the software. Unit tests essentially yield a list of results, requiring that the user to take those results and find resolutions. At Inkling, within our cloud publishing environment Habitat, unit tests are regularly run on projects to catch errors before they spread. The tests look for problems in the code, like broken file references in the table of contents or empty hrefs that do not specify a link location.
Essentially, these tests represent the collective experience of our editorial teams over many years of learning what errors are common to digital content projects. Within Habitat, for ease of use, the results of these unit tests come equipped with links to the source of the issue and a description of the error at hand. This is significantly more efficient than, say, combing through each instance of an href in a title and looking for empty ones; instead, we can follow unit test links to fix the issue immediately. A process that would’ve taken hours and been fraught with possibility for error is now completed in minutes.
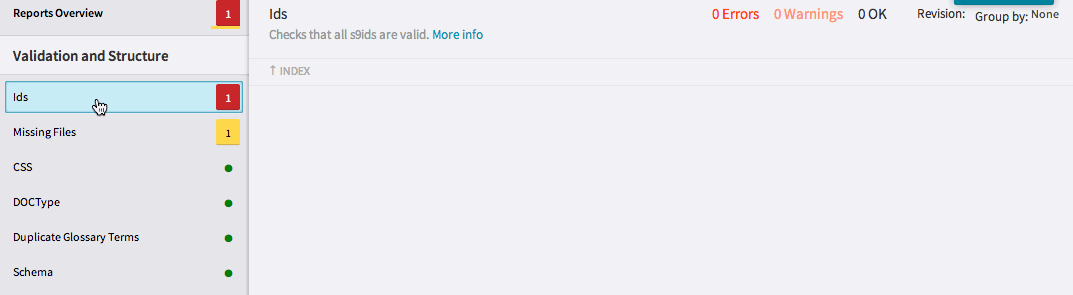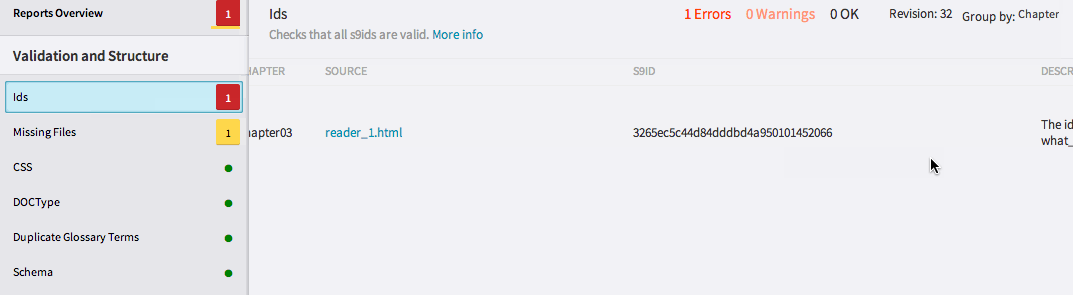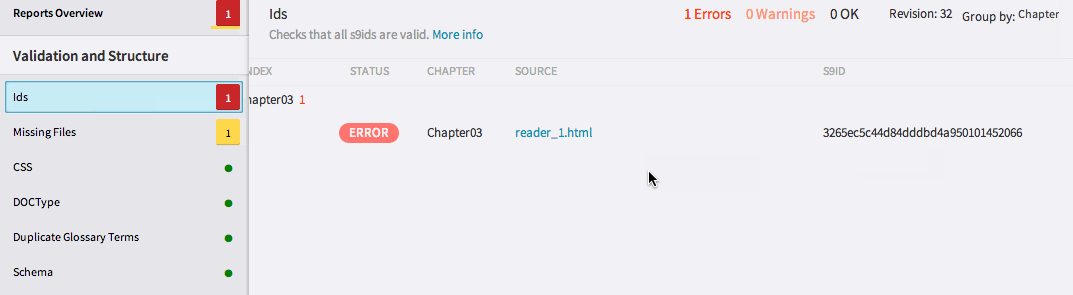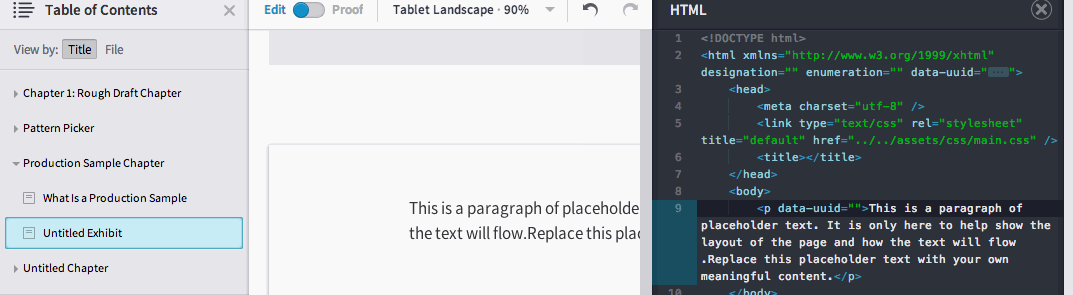
Unit reports
Building Tools to Maintain Quality for You
After unit tests, the next step is creating interactive proofing tools that test a single aspect of a digital product. For example, a digital textbook can have thousands of glossary terms and footnotes. At Inkling, we treated these elements as tappable text that expands into a bubble containing the related information. How do we test for quality across all of these elements? One way might be to tap each glossary term in a project. However, just as we saw with checking errors before unit tests, this manual way is painful, expensive, and prone to human error.
Another possibility might be searching through the code, looking for aberrations where a term might be erroneously linked with the wrong definition–depending on the neatness of your glossary structure, this is only marginally less tedious and accurate than the first way. A third option, though, is to build a tool with the sole purpose of demonstrating the functionality of these tappable terms. At Inkling, we’ve tried all three methods and have found the third way as the most efficient and accurate.
Using this tool within Habitat, you can see, at a glance, every word in a file that is associated with a term. You can check that the terms match, so that you can ensure that similar terms have not been mismatched. The glossary becomes instantly, automatically proofable, through a slick combination of humans and machines. By using the aggregate knowledge of how tricky glossary terms are to proof and by understanding what is relevant when it comes to quality, we were able to build a tool that embraces the codified nature of digital content.
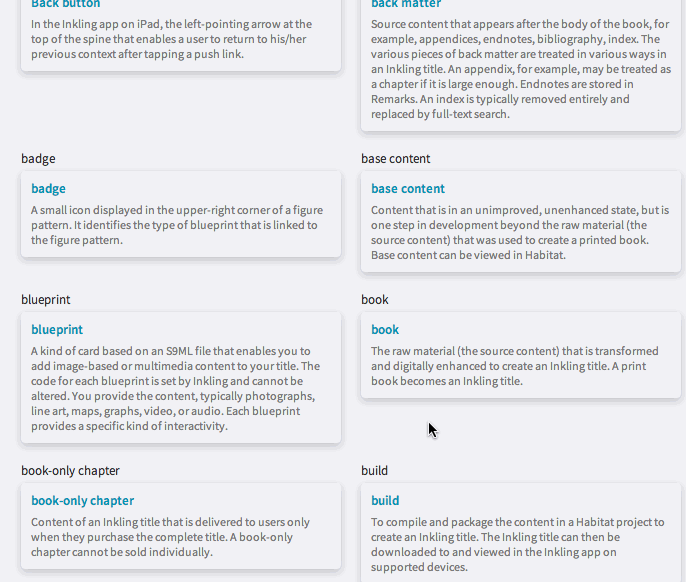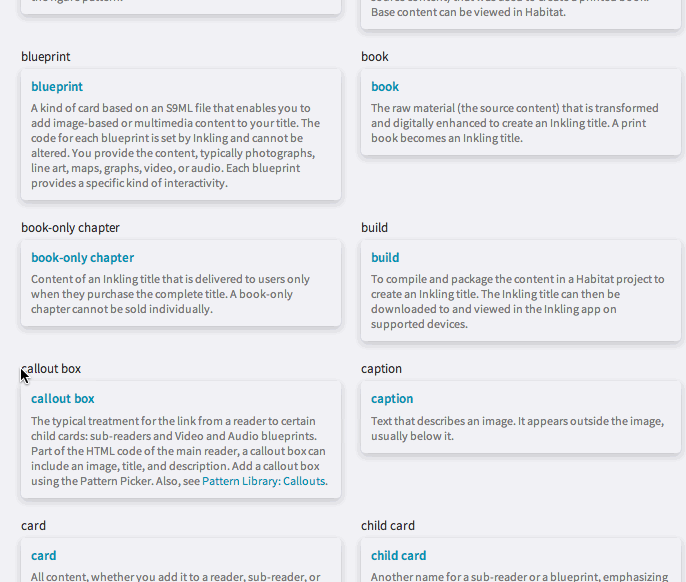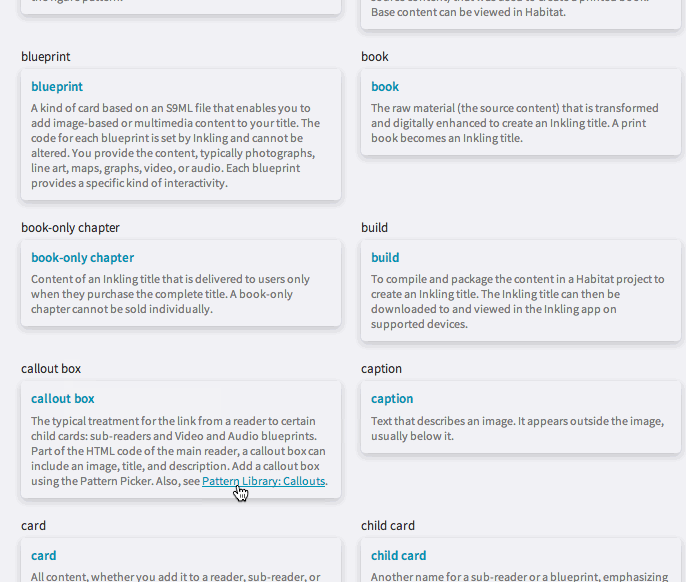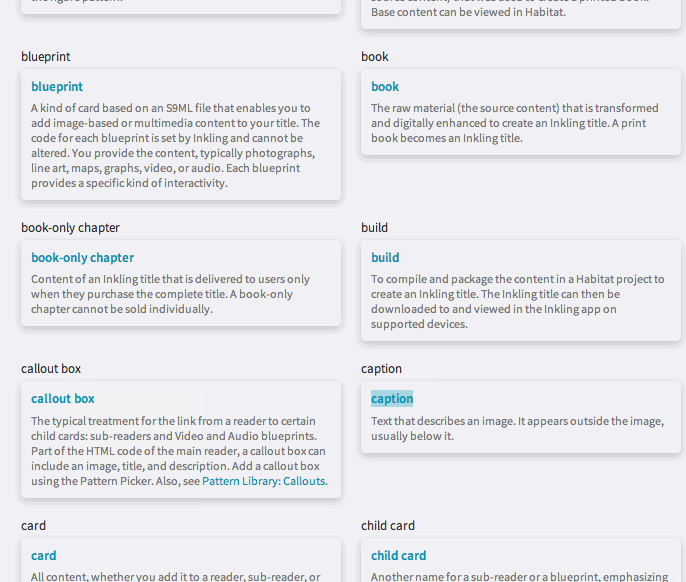
Glossary
The Hunt for Better Content
When you appreciate that digital content is steeped in code, you can open yourself up to new world of tools. Learning markup languages and understanding how code connects to content might be new territory for editorial teams, but, ultimately, it is more empowering to have a world of content became imminently more accessible. The code is almost like a treasure map, where little X’s mark the spots lying beneath the surface–all you have to do is start digging, and see what you can turn up.
What do you think? How has learning to treat content as code changed the way you and your teams create and publish? Let us know what you think in the comments below!
About the Author